Executive summary
AI services are becoming essential, but many companies are walking into two avoidable problems: vendor lock-in and unpredictable token costs.
Research like FrugalGPT highlights why this matters: LLM APIs have “heterogeneous pricing structures” and fees that can differ by two orders of magnitude, making large-scale usage expensive without cost controls. [1]
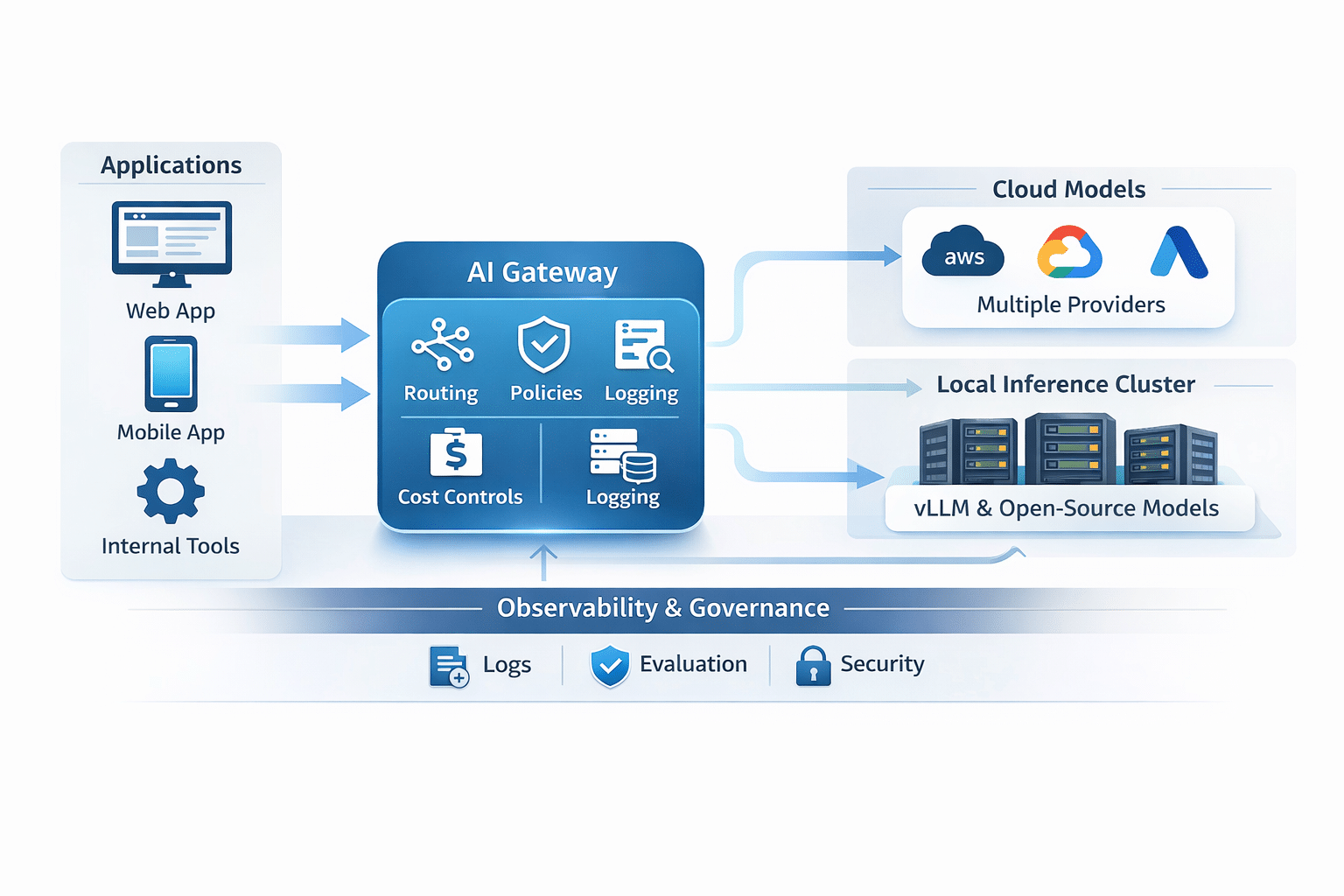
A model-agnostic gateway pattern is the antidote. With an OpenRouter-style approach, you can use one unified integration layer and switch models (and even providers) based on task, cost, and performance, with automatic fallbacks if a provider fails or rate limits you. [2]
A truly durable strategy is hybrid AI architecture: route some tasks to cloud models and run other tasks on locally hosted open-source models for privacy, latency, and savings. Serving stacks like vLLM support high-throughput inference and provide an OpenAI-compatible API server, which makes porting and swapping models far easier. [3]
To do this responsibly, governance and security must be designed in, not bolted on. NIST’s AI Risk Management Framework (NIST AI RMF) emphasizes integrating Test, Evaluation, Verification, and Validation (TEVV) throughout the AI lifecycle. [4] OWASP’s Top 10 for LLM Applications enumerates real risks like prompt injection, insecure output handling, sensitive information disclosure, and excessive agency. [5]
This article lays out the architecture, the decision logic for cloud vs local hosting, multi-model strategies, observability and cost accounting, governance and security guardrails, and a practical implementation roadmap. Scheduling and weekly publication workflows are outside this research task.
Why hybrid AI architecture exists in the first place
If you are a business buyer, you probably do not care about models as a hobby. You care about outcomes: faster support, better analytics, automated internal workflows, smarter customer experiences.
But the moment you build on a single platform, you inherit its future pricing, availability, and product decisions. That is the lock-in problem.
Then comes the “AI cost surprise.” FrugalGPT documented that LLM fees can vary by two orders of magnitude, and that using LLMs at scale can be expensive. [6] Even if you love today’s pricing, your budget may not love next year’s pricing.
Hybrid AI architecture is a practical response:
- Use cloud models where they genuinely add value.
- Use local models for routine tasks where “good enough” is good enough.
- Route requests through a model-agnostic gateway so the app is not welded to a single model or provider.
- Track cost per task, not just “token usage.”
This is not an academic exercise. It is how you keep AI useful when the landscape changes.
The model-agnostic gateway pattern
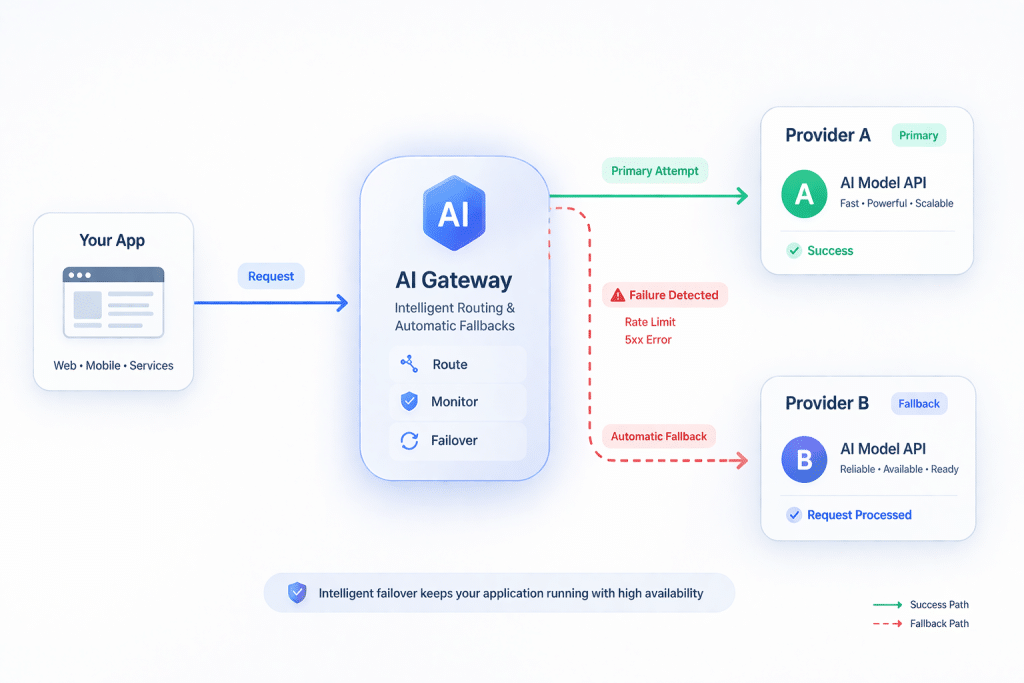
A model-agnostic gateway is the control plane for your AI system. Your application talks to one interface. The gateway decides which model serves the task and can fail over when needed.
OpenRouter is a useful example of this pattern because its documentation is explicit about core behaviors:
- It provides a unified API endpoint that gives access to many models and “automatically handles fallbacks and selecting the most cost-effective options.” [7]
- Its API reference states it will select “the least expensive and best GPUs available” and “fall back to other providers or GPUs” if it receives a 5xx response or you are rate-limited. [8]
In practical terms, a gateway enables three things business leaders care about:
Portability
You can switch models without rewriting your application.
Resilience
If a provider is down or rate-limiting, the system can fail over. [8]
Cost control
You can route tasks to a cheaper model when it meets requirements and reserve expensive models for high-value steps.
Local hosting with vLLM (and when it pays off)
Local hosting is the part that makes “hybrid” real. If your AI system always calls a cloud model, you can still do routing and cost optimization, but you are not getting privacy and unit-economics leverage.
vLLM is a widely used open-source serving engine for LLM inference and has a few properties that make it ideal for hybrid deployments:
- It emphasizes high throughput and includes techniques like PagedAttention and continuous batching. [9]
- It provides an OpenAI-compatible API server, which is a big deal for portability. [3]
That OpenAI-compatible interface means your application (or gateway) can often point to either cloud or local endpoints using the same request shape, reducing lock-in at the application layer. [3]
Cloud models vs local models: a decision framework
This is where many businesses go wrong. They pick “the best model” and apply it everywhere.
A smarter approach is to map model choice to task type. Use local open-source models for routine, well-bounded work; use cloud models for complex reasoning, higher-stakes outputs, and edge cases.
| Task type | Typical tolerance for error | Good fit | Why |
| Classification, tagging, routing | Low to medium | Local open-source (vLLM) | Fast, cheap, predictable; can be tuned to your labels |
| Extraction (forms, invoices, structured text) | Low | Local or hybrid | Can run locally when data sensitivity matters; escalate on uncertain cases |
| Summarization of internal docs | Medium | Local or hybrid | Local for privacy; cloud for complex summarization |
| Customer-facing “final answer” | Medium to high | Hybrid | Start local for drafts, use cloud for final polish or high-risk prompts |
| Multi-step tool planning and high-level decision support | High | Cloud | More capable models are usually safer for complex reasoning |
| High-compliance or sensitive data workflows | High | Local-first | Keep data in your environment when possible |
The key is not ideology. It is measured performance and cost per task.
Multi-model strategies: routing, cascades, and ensembles
Hybrid AI architecture is not only “cloud vs local.” It is also “which model for which moment.”
FrugalGPT formalizes the cost-performance problem and outlines strategies to reduce inference cost, including LLM cascades. [10] It presents FrugalGPT as an instantiation of an LLM cascade that learns which combinations of LLMs to use for different queries and reports results like matching the best individual LLM’s performance with up to 98% cost reduction in their experiments. [11]
You do not have to implement a research paper verbatim to use the idea. In production, cascades and ensembles typically look like this:
Cascades (escalation routing)
- Run the cheapest acceptable model first (often local).
- Score the answer (confidence checks, rule checks, evaluator model checks).
- Escalate to a stronger model only if needed.
This is where major savings come from: most queries are routine, but most budgets get burned by treating every query like it is mission-critical.
Ensembles (parallel collaboration)
- Run two models on the same input (for example, one cloud, one local).
- Compare outputs using scoring rules or an evaluator.
- Choose the best answer or synthesize a consensus.
This “collaboration” pattern is especially useful when accuracy matters and you want to reduce reliance on a single model’s blind spots. It also helps you discover which model is best for each task category using real production data.
Model routing (policy-based selection)
Routing is the operational version of your business rules:
- “All PII-sensitive requests go local-first.”
- “All external customer responses must pass a safety filter and a policy check.”
- “Use model A for extraction; model B for summarization; model C for final customer tone.”
OpenRouter-style gateways are built around this idea of choosing models and providers under one endpoint, including fallbacks. [2]
Cost and observability: token accounting is not optional
If you cannot explain your AI cost per task, you cannot control it. And if you cannot control it, your finance team will eventually control it for you.
OpenRouter’s documentation is unusually direct about usage accounting:
- It provides built-in usage accounting and returns token counts and cost information directly in API responses. [12]
- It lists prompt and completion token counts, cost, reasoning token counts (if applicable), and cached token counts. [12]
- It also describes querying generation stats (including token counts and cost) via a /api/v1/generation endpoint using the returned request id. [13]
This matters because it supports reliable reporting:
- cost per workflow (classification vs summarization vs complex reasoning)
- cost per customer interaction
- cost per internal report generated
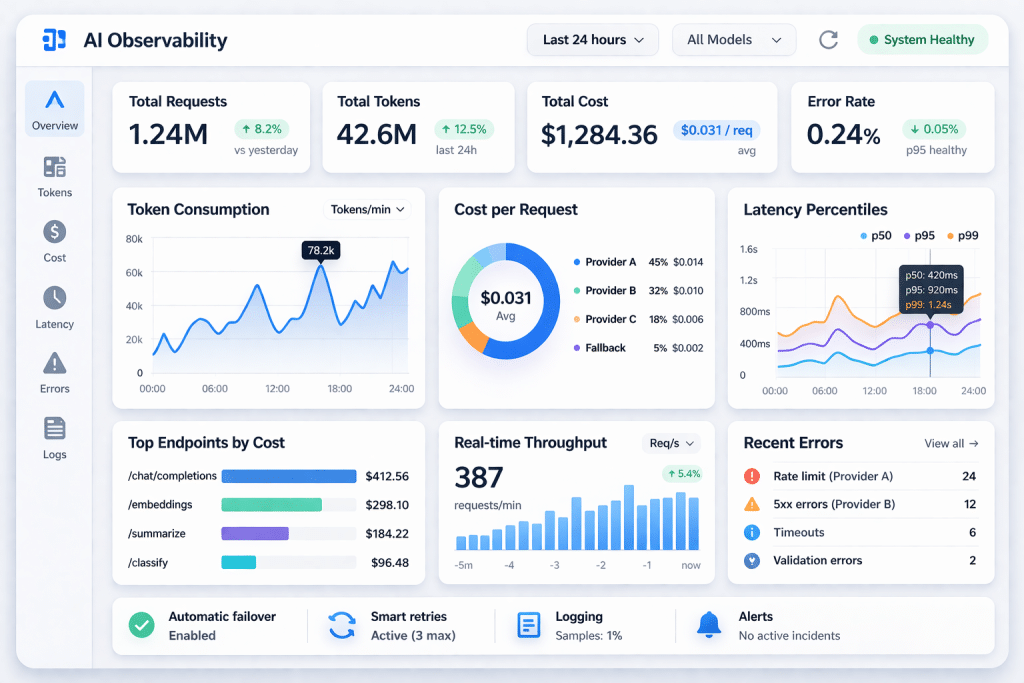
Leadership reporting metrics (short list)
If you want leadership buy-in, keep metrics short and defensible:
- AI cost per task category (and trend)
- Total monthly AI spend (and spend per department)
- p50 and p95 latency per task category (user experience and throughput)
- Accuracy/acceptance rate (how often outputs are used without rework)
- Escalation rate (how often the cascade had to call the expensive model)
- Safety incident rate (blocked prompts, policy violations) based on OWASP risk categories [5]
Governance and TEVV (Testing, Evaluation, Verification, and Validation): The system must improve over time
A hybrid AI system is not “set it and forget it.” Models change, data changes, and your business rules change. That is why governance is part of the architecture, not a compliance afterthought.
NIST AI RMF explicitly integrates TEVV into the AI lifecycle and notes that TEVV tasks performed regularly can provide insights and allow for mid-course remediation and post-hoc risk management. [14] The AI RMF also includes GOVERN categories that address third-party software and data supply chain issues, including policies and procedures for handling failures or incidents in third-party data or AI systems deemed high-risk. [15]
That aligns perfectly with the vendor lock-in problem. A model-agnostic, hybrid approach is not just about price. It is also about reducing supply-chain risk by designing contingency paths.

What TEVV looks like in practice
For business readers, TEVV becomes a repeatable operating discipline:
- Test sets and evaluation metrics for each major task type
- Ongoing monitoring (accuracy, drift, latency, cost)
- Periodic re-validation when you change models, prompts, or data
- Incident reviews when something fails or behaves unexpectedly
NIST notes that TEVV tasks can be incorporated as early as design and include ongoing monitoring in operations. [16]
Security risks you cannot ignore (OWASP LLM Top 10)
Security for LLM applications is now well-defined enough to build checklists around it.
OWASP’s Top 10 for Large Language Model Applications includes:
- Prompt Injection (LLM01) [5]
- Insecure Output Handling (LLM02) [5]
- Training Data Poisoning (LLM03) [5]
- Model Denial of Service (LLM04) [5]
- Supply Chain Vulnerabilities (LLM05) [5]
- Sensitive Information Disclosure (LLM06) [5]
- Insecure Plugin Design (LLM07) [5]
- Excessive Agency (LLM08) [5]
- Overreliance (LLM09) [5]
- Model Theft (LLM10) [5]
Hybrid architecture affects these risks in two ways:
- Local hosting can reduce exposure for sensitive data, but it does not automatically eliminate prompt injection risks.
- Multi-model workflows can increase attack surface if you do not enforce consistent policies and validation across all model calls.
This is why eLink treats security as part of the system design: input validation, output constraints, safe tool execution, and guardrails around when an AI is allowed to take action.
Implementation roadmap: how eLink builds this without chaos
Many companies can experiment with AI; fewer can operationalize it. Our job is to get you to production safely and keep it stable.
Discovery and design
- Identify highest-value workflows (support, ops, analytics, knowledge retrieval).
- Define success metrics and budget constraints.
- Classify data sensitivity and set routing rules (local-first vs cloud).
- Design the gateway layer and the fallback strategy.
Pilot with tight scope
- Implement one workflow end-to-end, including logging and cost accounting.
- Establish a baseline and compare against pilot metrics (latency, cost per task, acceptance rate).
- Run TEVV-light: test sets, safety checks, and basic red-team prompts aligned to OWASP categories. [17]
Integrate and scale
- Expand to additional workflows and departments.
- Implement cascades where appropriate (cheap model first, escalate as needed), informed by FrugalGPT-style strategy. [18]
- Add local inference cluster for routine tasks to reduce cloud spend, using vLLM for serving with an OpenAI-compatible interface. [3]
Monitor and optimize
- Weekly reporting: cost per task, latency p95, escalation rate, incident count.
- Quarterly model review: test new models, swap in better options without rewriting the application (gateway pattern).
- Continuous improvement: refine prompts, evaluators, and routing policies.
Scheduling note: ongoing publishing cadence and reminders are outside this research task. This roadmap is written to fit into eLink’s normal delivery cycle for client projects.
Practical checklist for a hybrid AI build
Use this as the implementation scorecard. If a vendor cannot explain how they handle these items, you are buying uncertainty.
| Category | What “done” looks like | Why it matters |
| Model-agnostic gateway | App talks to one interface; models can be swapped behind it; routing rules exist | Avoids lock-in; enables fast iteration |
| Cloud routing and fallback | Automatic fallback on 5xx and rate limits; provider diversity | Reduces downtime; improves reliability [8] |
| Local inference cluster | vLLM serving open-source models; OpenAI-compatible API endpoint | Privacy and savings; portability [9] |
| Multi-model strategy | Cascades or ensembles tested; escalation rules defined | Cuts cost while protecting quality [19] |
| Cost controls | Token and cost accounting per request; budgets and alerts | Prevents runaway spend [20] |
| Observability | Central logs, traces, and dashboards; per-workflow metrics | Makes problems diagnosable, not mysterious |
| Data handling policy | Clear rules for PII, retention, and where data can flow | Reduces compliance and reputational risk |
| Output validation | Structured outputs when needed; sanitization before tool actions | Mitigates insecure output handling [5] |
| Security testing | Prompt injection tests; red-team scenarios; incident playbook | Aligns to OWASP LLM risks [5] |
| TEVV discipline | Evaluations planned, run, documented, and repeated | Enables safe change over time [4] |
Kentucky note: why this matters locally
Kentucky businesses often operate with lean teams and very practical budgets. When token costs rise or a vendor changes terms, it is not “an innovation story,” it is a line item. A model-agnostic hybrid AI architecture reduces that risk: routine work can run locally, sensitive workflows can stay closer to home, and your system can shift models as the market changes.
We build these systems in a way that fits how regional businesses actually operate: measured, cost-aware, and focused on results.
How eLink delivers hybrid AI services
At eLink Design, we do not sell “a model.” We deliver an AI system: routing, security, governance, observability, and measurable outcomes.
If your company wants AI that is fast today and still sane two years from now, the model-agnostic hybrid approach is the grown-up architecture.
When you are ready, our next step is a short discovery phase, a scoped pilot, and measurable reporting that demonstrates impact (cost per task, latency, quality trend) before you scale.
Let’s get started
If you want hybrid AI architecture built for privacy, savings, and long-term flexibility, hire a team that builds production systems, not prototypes. We can help you design the gateway layer, deploy local inference where it makes sense, integrate cloud routing for advanced tasks, and implement the governance and security discipline that keeps the system stable.
About eLink Design (Kentucky-based team)
https://www.elinkdesign.com/company/about-elink
Contact eLink to scope a hybrid AI system
https://www.elinkdesign.com/company/contact-us
Sources
OpenRouter Quickstart (unified API, fallbacks, cost-effective options)
https://openrouter.ai/docs/quickstart
OpenRouter API Reference (model routing, fallbacks; generation stats endpoint; token counts and cost)
https://openrouter.ai/docs/api/reference/overview
OpenRouter Usage Accounting (token counts, cost, caching status in responses)
https://openrouter.ai/docs/guides/administration/usage-accounting
vLLM documentation (PagedAttention, continuous batching, OpenAI-compatible API server)
https://docs.vllm.ai/en/v0.7.3/index.html
vLLM GitHub repository (OpenAI-compatible API server and capabilities)
https://github.com/vllm-project/vllm
FrugalGPT (pricing differs by two orders of magnitude; cascades; up to 98% cost reduction claim in experiments)
https://arxiv.org/abs/2305.05176
NIST AI Risk Management Framework (AI RMF 1.0) – TEVV across lifecycle; third-party supply chain risk governance
https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf
OWASP Top 10 for Large Language Model Applications (risk categories)
https://owasp.org/www-project-top-10-for-large-language-model-applications/
[1] [6] [11] [19] [2305.05176] FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
https://arxiv.org/abs/2305.05176
[2] [7] [21] OpenRouter Quickstart Guide | Developer Documentation | OpenRouter | Documentation
https://openrouter.ai/docs/quickstart
[3] [9] Welcome to vLLM — vLLM
https://docs.vllm.ai/en/v0.7.3/index.html
[4] [14] [15] [16] Artificial Intelligence Risk Management Framework (AI RMF 1.0)
https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf
[5] [17] OWASP Top 10 for Large Language Model Applications | OWASP Foundation
https://owasp.org/www-project-top-10-for-large-language-model-applications
[8] [13] OpenRouter API Reference | Complete API Documentation | OpenRouter | Documentation
https://openrouter.ai/docs/api/reference/overview
[10] [18] FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
https://arxiv.org/abs/2305.05176?utm_source=chatgpt.com
[12] [20] Usage Accounting | Track AI Model Usage with OpenRouter | OpenRouter | Documentation
https://openrouter.ai/docs/guides/administration/usage-accounting

